
안녕하세요, 빅픽처 인터랙티브 프론트엔드(FE) 박성렬입니다.

개발자에게 현지화(localization)는 매우 수고로운 일입니다. 현지화에 사용될 문자열을 관리하는 일은 말할 것도 없습니다. 현지화 관리가 왜 어려운지, 그리고 이를 빠른 속도로 진행되는 애자일 환경에서 어떻게 대처할지에 대해 소개합니다.
왜 현지화 문자열 관리가 어려운가요?
현지화는 매우 깊고 넓은 영역입니다. 현지화 자체의 어려움에 대해서는 나중에 별도의 문서로 다루도록 하겠습니다. 여기서는 현지화 문자열 관리가 왜 어려운지만 다루어 보겠습니다.
현지화 문자열은 일반적으로 개발팀의 외부에서 관리합니다. 규모가 있고 분업이 충분히 이루어진 개발팀일수록 세부 서비스(혹은 정책)의 복잡도는 매우 높기 때문입니다. 그리고 문자열의 배치는 보통 디자인을 거쳐서 개발팀에 전달됩니다. 즉 아래와 같은 상상을 해볼 수 있습니다.
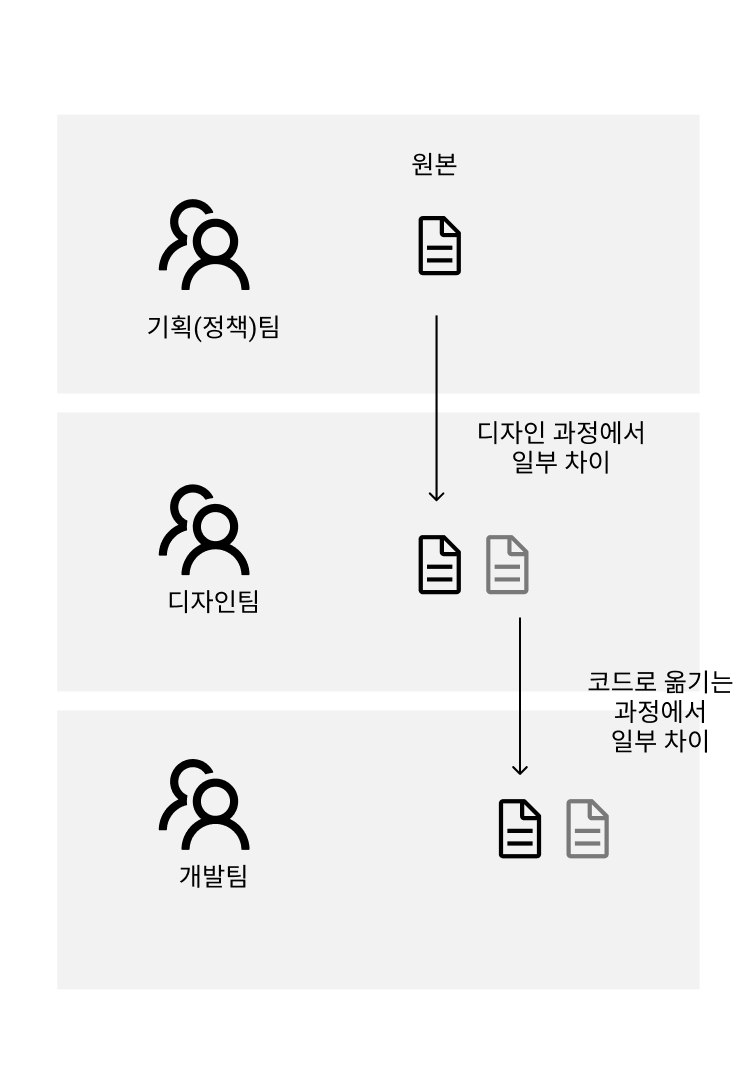
하나의 문자열은 입안 이후 각각 디자인과 개발팀을 모두 거치면서 문자열이 조금씩 바뀌게 됩니다. 이유는 여러가지입니다.
- 오타
- 기획 또는 디자인이 뒤늦게 수정되고 전달이 안되었을 경우
- 문서에서 실수로 문자열을 잘못 본 경우
각 단계에서 이 모든 과정이 완전히 무결하기는 매우 어렵기 때문에 개발팀에서 만든 결과물은 항상 약간의 실수가 끼어들 수밖에 없습니다. 게다가 이것은 순전히 신규 개발만을 상정했을 때의 이야기입니다. 수정하는 과정은 조금 더 복잡합니다. 기획팀에서 이전에 개발팀에서 만들어낸 실수를 모두 파악해야 합니다.
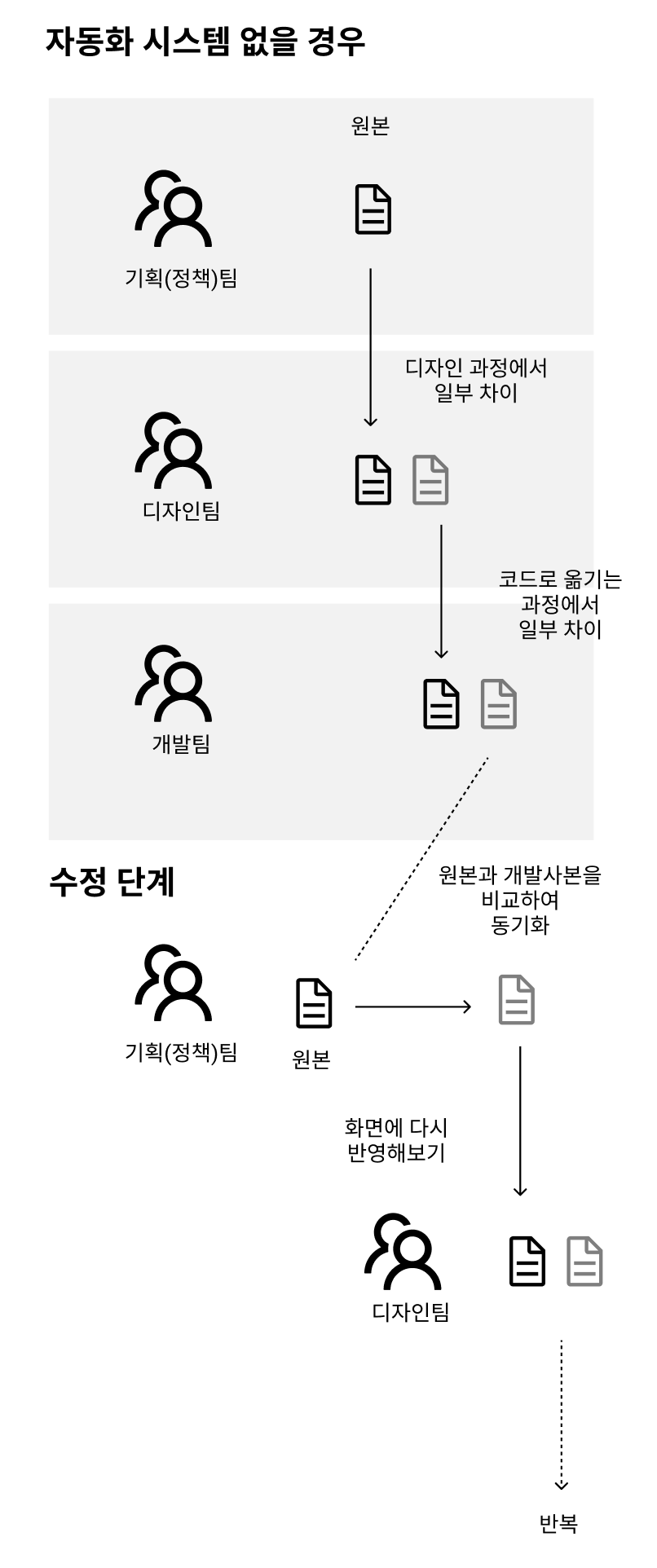
다시 개발에 내용이 전달되기 위해서는 디자인팀을 거치며 디자인 이상을 파악해야합니다. 거기에 동기화라는 과정이 추가되면서 오히려 개발보다 더 길어진 것을 볼 수 있습니다.
따라서 개발 패러다임인 단일화된 진실(single source of truth), 우리에게 좀더 친근한 표현으로는 원 소스 멀티 유즈(one source multi use)를 생각해 볼 수 있습니다.
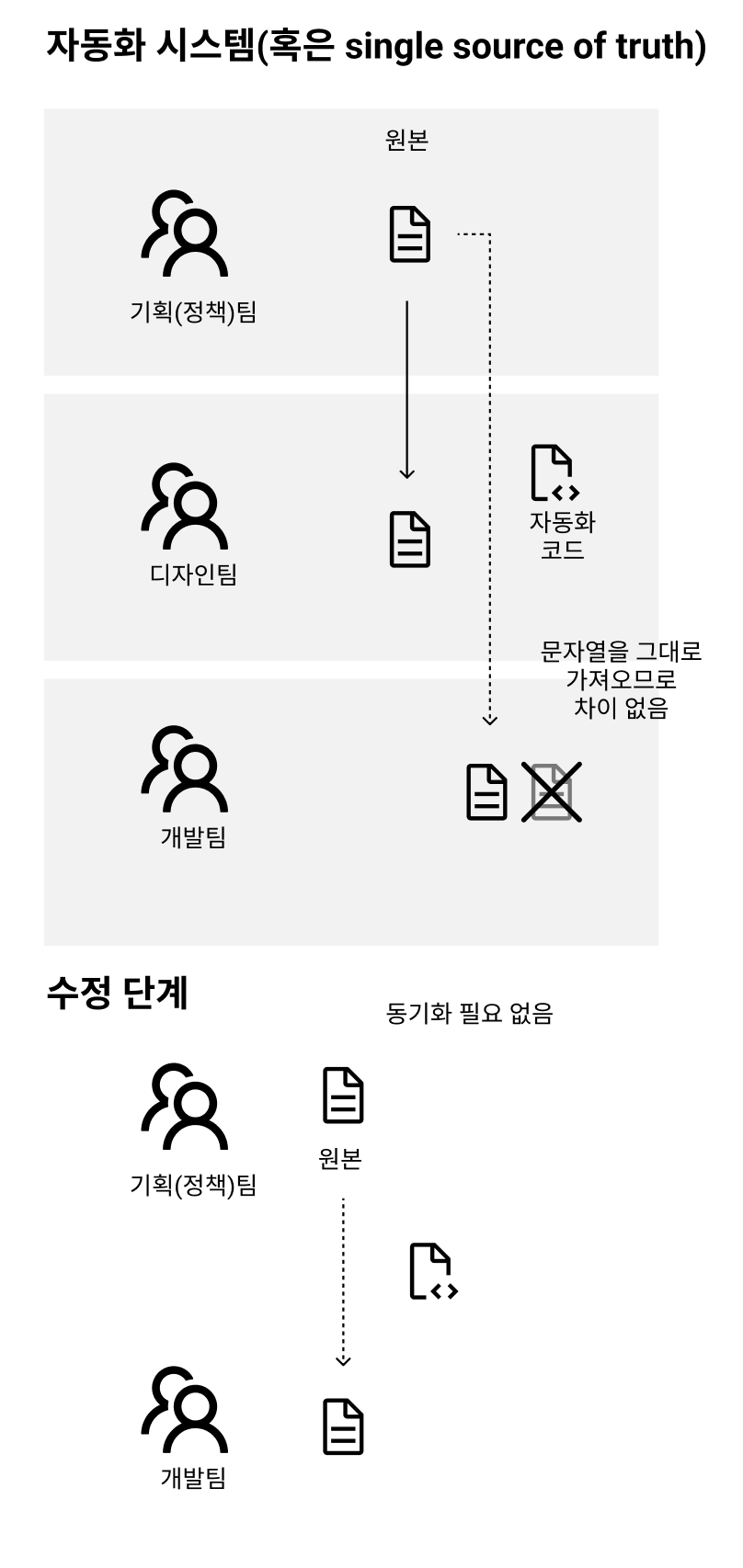
자동화를 거치면 사람의 개입 없이 모든 과정이 기계적으로 진행되므로 원본과 똑같은 사본이 생성되는 것과 마찬가지입니다. 따라서 동기화가 불필요하고 인재로 인한 사고를 예방할 수 있습니다.
실무에서 관리하는 방식: 구글 스프레드시트
문자열 관리를 시스템화하거나 자동화 할 때 보통은 LaaS(Localization as a Service) 관리 도구를 이용하여 관리하게 되는 경우가 많습니다. 이 내용을 이전에 개인 문서에 정리해 두었으니 궁금하신 분은 참조하셔도 좋을 것 같습니다.
이번에도 개인 프로젝트의 경험을 살려 LaaS 도입을 목표로 하고 있으나, 현지화에 당장 많은 리소스를 투입하기는 팀에게 매우 부담스러울 것 같았습니다.
따라서 최대한 작은 분량의 작업을 통해 문자열 관리를 시스템화 하기로 했습니다. UI로는 구글 스프레드시트가 가장 적당해 보였습니다.
- 이미 빅픽처 인터랙티브의 기획과 정책 관리 과정이 상당수 구글 문서를 통해서 이루어지고 있음
- 여러 사람들이 사용하며 UI의 편의성이 이미 검증되었음
- 입력도구에 별도의 개발이 필요하지 않음
우선 구글 스프레드시트에 문자열과 문맥, 혹은 키와 문자열 값을 아래와 같이 정리했습니다.

왼쪽에는 .json 파일에 들어갈 키값을 nested 형태로 적어주고, 오른쪽에는 i18n문자열을 정리합니다. 왼쪽에 key, 오른쪽에 value 형태로 관리합니다.
직접 구성한 워커(worker) 앱을 이용해 자료는 아래와 같이 변형됩니다.
- 구글 스프레드시트에 자료 입력
- 불필요한 자료를 걷어내고(셀 크기 등) tsv로 변환
- json으로 변환
작업이 완료되면 파일>공유>웹에 게시를 선택하여 .tsv형태로 내보냅니다. .csv를 사용해도 되지만, 쉼표는 현지화 과정에서도 자주 사용되기 때문에 탭 여백(tab)을 구분자(delimiter)로 사용합니다. 웹에 게시를 선택하면 나오는 URL을 가지고 GET 요청을 하면 .tsv 파일을 그대로 받아올 수 있습니다.
- tsv - 탭을 구분자로 하는 자료형태
- csv - 쉼표를 구분자로 하는 자료형태
- tsv와 csv의 차이 바로알기
자동화 1: Github Flat Data
Github Flat Data깃헙 플랫 데이터란 Github Action(이하 깃헙 액션) 서비스의 일부로, 데이터사이언스를 위해 주기적으로 데이터 마이닝 작업을 하여 정규화된 자료(normalized data 혹은 flat data)를 자동으로 가져오는 기능입니다. 쉽게 말하면 POSIX의 스케줄러인 cron 형태로 돌릴 수 있는 깃헙 액션입니다.
- 인스턴스를 직접 운용하지 않기 때문에 서비스 개발을 위한 부담이 매우 적다
- 깃헙 액션을 이용하므로 비용이 무료.
구글 스프레드시트와 마찬가지로 애자일한 환경에서 빠른 속도로 현지화를 구성할 수 있기에 알맞다고 생각하여, 플랫 데이터를 활용하여 현지화 파일을 가져오도록 구성해 보았습니다.
코드에 아래와 같이 Github Workflow(깃헙 워크플로우)를 추가했습니다.
# $WORKSPACE/.github/workflows/flat.yml
# github flat data를 위한 github workflow 파일
name: data
on:
schedule:
- cron: "*/30 * * * *" # 30분에 한 번씩 요청합니다.
workflow_dispatch: {}
push:
branches:
- main
paths:
- .github/workflows/flat.yml
- ./postprocessing.ts # deno 타입스크립트를 통해 후처리합니다.
jobs:
scheduled:
runs-on: ubuntu-latest
steps:
- name: Setup deno
uses: denoland/setup-deno@main
with:
deno-version: v1.10.x
- name: Check out repo
uses: actions/checkout@v2
- name: Fetch data
uses: githubocto/flat@v3
with:
http_url: https://docs.google.com/spreadsheets/d/e/.../pub?output=tsv # 구글 스프레드시트 url입니다
downloaded_filename: raw_data.tsv # raw_data.tsv로 저장합니다
postprocess: ./postprocessing.ts # deno 타입스크립트를 통해 후처리합니다.깃헙 플랫 데이터는 데이터 기본 후처리 기능에 deno 코드를 지원합니다. 또한 deno 코드 내부에서는 플랫 데이터 공식 라이브러리를 통해 tsv 해석 기능과 json 저장 기능을 사용할 수 있습니다. 공식 문서를 참조하여 후처리를 할 deno 타입스크립트 파일을 만들어줍니다.
// postprocessing.ts
import {
readCSV,
writeJSON,
} from "https://deno.land/x/flat@0.0.14/mod.ts";
import lodash from "https://cdn.skypack.dev/lodash";
// 빠른 코드 관리를 위해 자료 타입을 미리 선언해줍니다.
interface ISpreadSheetRow {
'key_2': string;
'ko_KR_2': string;
}
// tsv를 사용하므로 탭을 구분자 옵션으로 제공합니다.
const rows = await readCSV(filename, { separator: "\t" });
// 해당 github action이 제대로 돌아갔는지 파악하기 위해 최초1열만 표기합니다.
// 자료의 정합성을 판단하기 위해 tail 또는 head로 자료의 일부만 출력하는 것은 데이터 사이언스의 기본입니다.
console.log(rows[0]);
const koKR = {}
rows.forEach((row) => {
const r = (row as unknown) as ISpreadSheetRow;
// lodash를 통해서 nested된 key값을 생성하고 값을 넣어줍니다.
lodash.set(koKR, r["key_2"], r["ko_KR_2"])
})
// 마지막에 파일을 저장합니다
const newFilename = `i18n-data.json`;
await writeJSON(newFilename, koKR);
console.log("Wrote a post process file");작업이 완료되면 깃헙 워크플로우를 깃헙 리파지토리의 액션 탭에서 수동으로 트리거하여 잘 작동하는지 테스트합니다.


플랫 데이터는 기본적으로 코드 베이스가 바뀌었을 때에만 새롭게 git commit 을 하도록 되어 있으므로, 임의로 시트를 수정하고 위와 같이 액션을 수동으로 트리거하여 결과물을 확인해봅니다.
// 생성된 현지화 문자열 json 파일
{
"time": {
"relativeTime": {
"second": "방금",
"minute": "{0}분 전"
/* ... */
}
}
/* ... */
}이상 없이 기능이 구현되어서 마무리 되는 줄 알았는데, 예상하지 못한 이슈가 있었습니다. 깃헙 액션 횟수에 월별 rate limit이 존재한다는 것입니다. 팀에서 워낙 많은 기능을 깃헙 액션에 넣어두고 있다보니, 생각보다 빠르게 rate limit에 도달한 것 같았습니다. 따라서 깃헙 액션이 아닌 다른 환경에서 현지화 문자열을 시스템화 하기로 했습니다.
자동화 2: 젠킨스 + 도커
개발팀은 현재 CI-CD 대부분을 젠킨스 환경에서 구현합니다. 따라서 깃헙 액션 대신 젠킨스 환경을 활용하기로 하고 기존 개발 내역을 버리고 새롭게 작업했습니다.
# 프로젝트 초기화
# axios: tsv파일을 가져오기 위한 get 요청
# d3-dsv: tsv파일을 parse하기 위한 용도
# dayjs: 날짜를 commit명에 human readable 한 상태로 포함하기 위한 용도
# simple-git: 현지화 문자열이 적용될 프로젝트의 git에 접근하기 위한 용도
# ts-node, typescript : 타입스크립트
$ yarn add axios d3-dsv dayjs lodash simple-git ts-node typescript문제가 생길 경우 빠른 디버깅을 위하여 타입스크립트를 적용했습니다. 다만 이 과정에서 d3-dsv가 타입스크립트의 import 구문을 지원하지 않아 아래와 같이 브릿지 모듈을 추가습니다.
// $WORKSPACE/module-bridge.cjs
// https://stackoverflow.com/questions/70810061/cant-import-d3-geo-package-into-node-js-typescript-project
module.exports = {
d3_dsv: async function () {
return import('d3-dsv');
},
};젠킨스에서 언제든 옵션 수정이 용이하도록 환경 변수를 통하여 기능을 변경할 수 있도록 했습니다.
// env.d.ts
declare global {
namespace NodeJS {
interface ProcessEnv {
TSV_URL: string;
GIT_URL: string;
GIT_TOKEN: string;
DEST_FILE: string; // 읽고 변경할 파일명
GIT_BRANCH: string;
USER_NAME: string; // git에 사용할 유저명
USER_EMAIL: string; // git에 사용할 email
}
}
}
export {};후처리를 담당할 worker는 아래와 같이 작성했습니다. deno코드를 일반 타입스크립트로 바꾸고, 좀더 상세한 로그를 추가했습니다. 이 코드에서는 주석 대신 로그를 보면 대충 어떻게 작동하는지 알 수 있습니다.
// $WORKSPACE/index.ts
import axios from 'axios';
import { DSVParsedArray } from 'd3-dsv';
import { d3_dsv as raw_d3_dsv } from './module-bridge.cjs';
const {
GIT_TOKEN,
GIT_URL,
TSV_URL,
DEST_FILE,
GIT_BRANCH,
USER_NAME,
USER_EMAIL,
} = process.env;
import _set from 'lodash/set';
import _isEqual from 'lodash/isEqual';
import fs from 'fs';
import simpleGit from 'simple-git';
import dayjs from 'dayjs';
const log = (...arg: any[]) => console.log(...arg);
interface ISpreadSheetRow {
'key_2': string;
'ko_KR_2': string;
}
type ISpreadSheetData = DSVParsedArray<ISpreadSheetRow>;
const proc = async () => {
log('worker up and running...');
const res = await axios(TSV_URL);
if (res.status !== 200) {
log('failed to download google sheet');
return;
}
log('tsv downloaded');
const d3_dsv = await raw_d3_dsv();
const rows = d3_dsv.tsvParse(res.data) as ISpreadSheetData;
log(rows.slice(0, 1));
log('total rows: ', rows.length);
const koKR = {};
rows.forEach((row) => {
const r = row as unknown as ISpreadSheetRow;
_set(koKR, r['key_2'], r['ko_KR_2']);
});
log('data all processed...');
log('deleting previous git');
fs.rmSync('./lvup-fe', { recursive: true, force: true });
log('cloning git');
// clone to ./lvup-fe directory
await simpleGit().clone(`https://${GIT_TOKEN}@${GIT_URL}`, 'lvup-fe');
log('clone finished');
const git = simpleGit('lvup-fe');
await git.checkout(GIT_BRANCH);
const strDate = dayjs().format('YYYY-MM-DD--HH-mm-ss');
const newBranch = `${GIT_BRANCH}-i18n-${strDate}`;
log('branched out to new branch');
await git.checkoutBranch(newBranch, `origin/${GIT_BRANCH}`);
let prevFile: any = '{}';
try {
prevFile = fs.readFileSync(DEST_FILE, 'utf8');
} catch (err) {
log('error while reading previous file', err);
}
const prevData = JSON.parse(prevFile);
const newData = JSON.stringify(koKR, null, 2);
fs.writeFileSync('./i18n-temp.json', newData);
const isEqual = _isEqual(prevData, newData);
if (!isEqual) {
log('diff found, updating...');
fs.writeFileSync(DEST_FILE, newData);
await git.add('.');
await git
.addConfig('user.name', USER_NAME)
.addConfig('user.email', USER_EMAIL);
await git.commit(`i18n updated to branch: ${newBranch} (${strDate})`);
await git.push('origin', newBranch);
} else {
log('diff not found. file not updated');
}
log('finished');
};
proc();도커 구성
작업이 완료되면 아래의 코드로 환경 변수가 잘 작동하는지 확인해봅니다.
# 중요 정보는 모두 숨김처리(REDACTED) 했습니다.
TSV_URL=https://docs.google.com/spreadsheets/d/e/.../pub?output=tsv \
DEST_FILE=./lvup-fe/.../i18n/data/coaching.json \
GIT_URL=github.com/.../lvup-fe \
GIT_TOKEN=... \
GIT_BRANCH=... \
USER_NAME=... \
USER_EMAIL=... \
yarn start이상 없이 작동하는 것을 확인하였으면 도커 파일을 작성합니다.
FROM node:lts-alpine3.14
RUN mkdir -p /home/node/app
COPY ./package.json ./package.json
COPY ./yarn.lock ./yarn.lock
RUN yarn install
RUN apk add git
COPY ./index.ts ./index.ts
COPY ./env.d.ts ./env.d.ts
COPY ./module-bridge.cjs ./module-bridge.cjs
COPY ./tsconfig.json ./tsconfig.json
CMD yarn start도커 컴포즈 파일을 작성하여 도커 실행시 환경 변수를 일괄적으로 제공하도록 했습니다.
version: '3.0'
services:
worker:
build:
context: .
dockerfile: ./dockerfile
environment:
- TSV_URL=$REDACTED_URL
- DEST_FILE=./lvup-fe/.../i18n/data/coaching.json
- GIT_URL=...
- GIT_TOKEN=...
- GIT_BRANCH=...
- USER_NAME=...
- USER_EMAIL=...
volumes:
- ./lvup-fe:/home/node/app/lvup-fe아래의 커맨드를 입력해서 잘 작동하는지 확인합니다.
docker-compose up이상 없이 작동하는 것을 확인했고, Jenkins Pipeline Script젠킨스 파이프라인 스크립트를 작성해서 파일이 구동되도록 합니다. 도커는 작성해 두었으므로, 도커를 사용해도 됩니다.
젠킨스 설정
우선 환경 변수에 1:1로 대응하는 젠킨스 string parameter를 만들고, 코드를 모르는 사람도 직관적으로 접근할 수 있도록 설명을 추가했습니다. 앞서 환경 변수를 통하여 프로그램을 조작할 수 있도록 하게 만든 이유입니다.
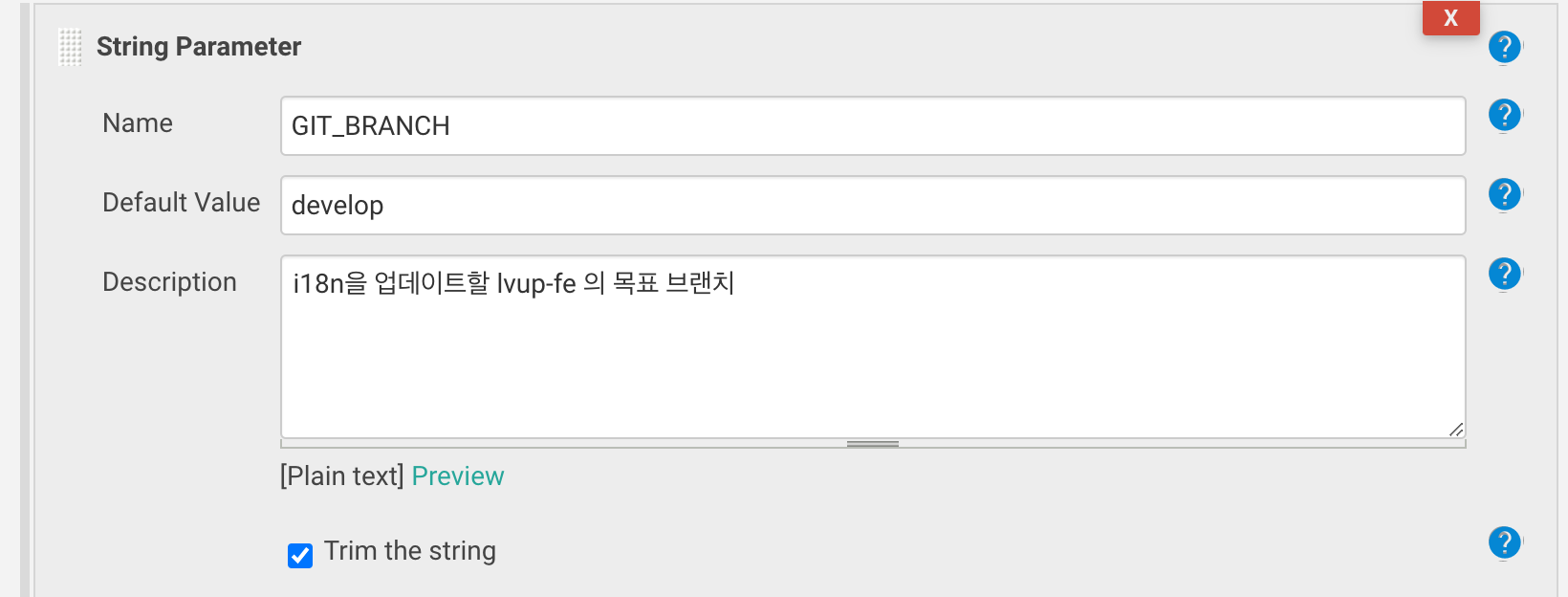
파이프라인 스크립트는 아래와 같이 구성했습니다.
node {
try {
// 여기에 작업 시작 알림 등 처리
stage('git checkout') {
git(
url: 'https://github.com/.../lvup-fe-i18n', // 워커 깃헙 리파지토리
credentialsId: ..., // 워커 리파지토리를 git clone할 계정(젠킨스로 관리)
branch: "${branch}" // 워커 브랜치
)
script {
// 워커 내의 환경 변수와 1:1로 대응한다
env.TSV_URL = "${TSV_URL}"
env.DEST_FILE = "${DEST_FILE}"
env.GIT_URL = "${GIT_URL}"
env.GIT_TOKEN = "${GIT_TOKEN}"
env.GIT_BRANCH = "${GIT_BRANCH}"
env.USER_NAME = "${USER_NAME}"
env.USER_EMAIL = "${USER_EMAIL}"
}
}
stage('yarn install') {
script {
sh '''yarn install'''
}
}
stage('Run script on lvup-fe') {
script {
sh '''yarn start'''
}
}
} catch (e) {
// 에러처리
throw e
} finally {
// 슬랙 알림 등 처리
}
}젠킨스에서 해당 파이프라인을 강제로 트리거해 보았습니다.
예상한 대로 깃 브랜치가 잘 생성된 것을 확인했습니다. 이제 이 브랜치를 머지하거나 PR하면 됩니다.

더 생각해볼 작업들
진행하면서 일부 작업을 건너 뛰었습니다.
- 젠킨스에서 바로 도커 실행 팀에서 이미 도커 운용을 하며 용량(메모리, 물리적 저장공간)을 많이 사용하고 있으므로, 최대한 적은 용량으로 운용하기 위해 노드만 사용했습니다. 도커를 사용할 경우 로컬과 같은 환경에서 테스트가 가능하므로 안정성은 보장됩니다. 그러나 이미지를 빌드하는 과정에서 별도의 빌드서버를 사용하지 않고 젠킨스 내부에서 빌드하기 때문에 빌드 과정에서 용량이 두 배로 나가게 됩니다.
- 젠킨스 내부에서의 스케줄러 실행 팀에서 불필요한 git commit 발생을 우려하여 스케줄러는 세팅하지 않았습니다.
- 현지화 문자열 수정을 배포 과정까지 연결 팀에서 현지화 문자열이 잘못 작성될 경우 리얼 서비스가 망가지는 것을 우려하여, 배포는 수동으로 진행하기로 했습니다.
- 피그마에 바로 현지화 동기화 일부 유료 LaaS 서비스에서는 피그마 플러그인을 제공해 바로 피그마에도 같은 환경을 설정할 수 있습니다. 외부 서비스를 사용하지 않았기 때문에 플러그인 사용은 다루지 않았습니다.
팀에 따라 세팅은 조금씩 바뀔 수 있습니다. 어디까지나 빅픽처 인터랙티브의 조건에 가장 맞는 환경으로 구성한 점을 유념하셔야할 것 같습니다.
맺으며
말이 안통하는 것도 서러운데 현지화 작업이란 여전히 고역입니다. 이러한 작업이 현지화의 모든 어려움을 해결할 수는 없겠지만, 외국인에게 유난히 불친절한 우리나라의 웹을 조금씩 발전시켜 나가면 좋을 것 같습니다.
'레벨업의 테크노트' 카테고리의 다른 글
| [유저리서치1] 어떻게 시작해야 할까? (0) | 2022.03.31 |
|---|---|
| [애자일로 빅픽처를 그리다] 데이터 대시보드 #2 (0) | 2022.03.07 |
| [더 나은 서비스를 위한 고민] 모달.. 어떻게 사용해야할까? (0) | 2022.01.26 |
| [애자일로 빅픽처를 그리다] 유저에게 효과적인 프로덕트를 전달하는 개발팀의 업무 흐름 (0) | 2022.01.18 |
| [프론트엔드]Node.js 메모리 누수 탐지하기 (0) | 2022.01.17 |




댓글